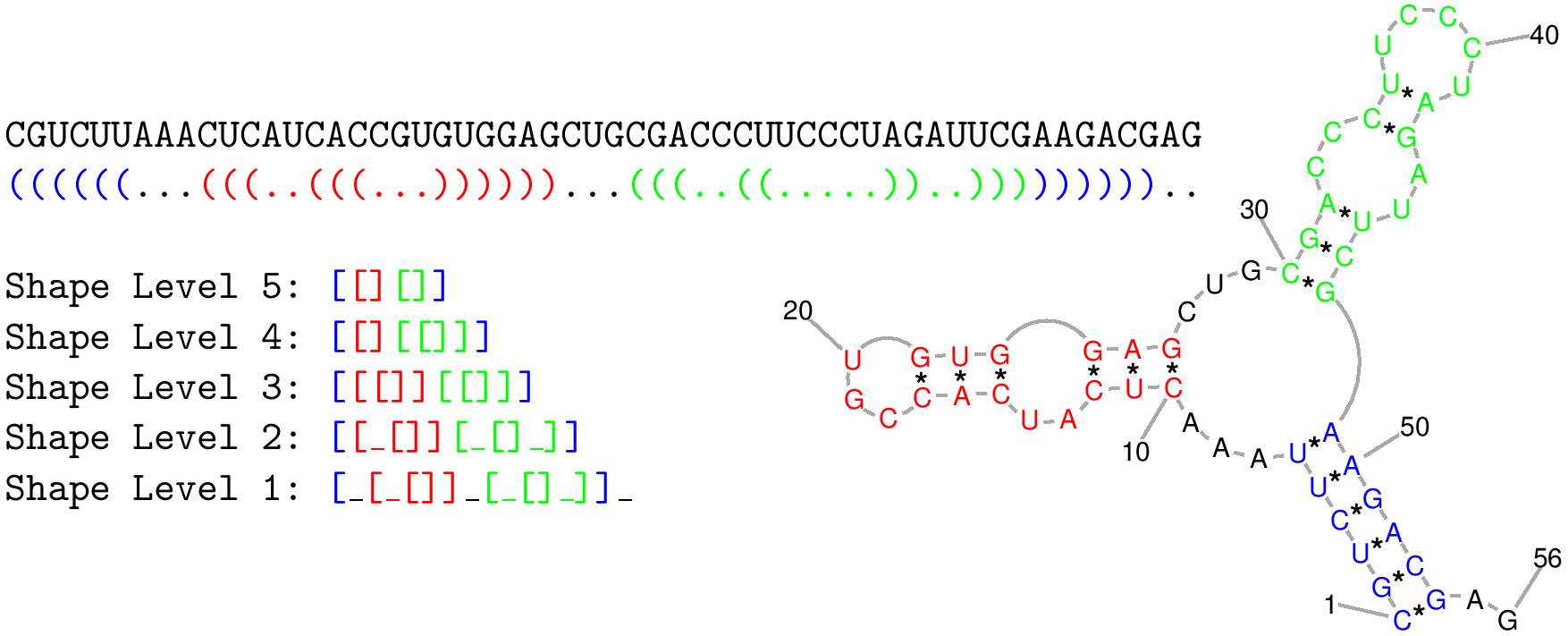Computes the single energetically most stable secondary structure for the given RNA sequence. Co-optimal results will be suppressed, i.e. should different prediction have the same best energy value, just an arbitrary one out of them will be reported. This resembles the function of the program RNAfold of the Vienna group (see [lor:ber:sie:taf:fla:sta:hof:2011] and [gru:lor:ber:neu:hof:2008]). If you only use "mfe" mode, consider switching to RNAfold, because their implementation is much faster, due to sophisticated low level C optimisations.
subopt
Often, the biological relevant structure is hidden among suboptimal predictions. In subopt mode, you can also inspect all suboptimal solutions up to a given threshold (see parameters absolute deviation and relative deviation). Due to semantic ambiguity of the underlying "microstate" grammar, sometimes identical predictions will show up. As Vienna-Dot-Bracket strings they seem to be the same, but according to base dangling they differ and thus might even have slightly different energies. See [jan:schud:ste:gie:2011] for details.
shapes
Output of subopt mode is crowded by many very similar answers, which make it hard to focus to the "important" changes. The abstract shape concept [jan:gie:2010] groups similar answers together and reports only the best answer within such a group. Due to abstraction suboptimal analyses can be done more thorough, by ignoring boring differences (see option shape level).
probs
Structure probabilities are strictly correlated to their energy values. Grouped together into shape classes, their probabilities add up. Often a shape class with many members of worse energy becomes more probable than the shape containing the mfe structure but not much more members. See [vos:gie:reh:2006] for details on shape probabilities.
Maybe you want to try our run-time heuristic RapidShapes [jan:gie:2010], which provides the same kind of analysis often much faster.
sample
Probabilistic sampling based on partition function. This mode combines stochastic sampling with a-posteriori shape abstraction. A sample from the structure space holds M structures together with their shapes, on which classification is performed. The probability of a shape can then be approximated by its frequency in the sample.
cast
For a family of RNA sequences, this method independently enumerates the near-optimal abstract shape space, and predicts as the consensus an abstract shape common to all sequences. For each sequence, it delivers the thermodynamically best structure which has this common shape. Since the shape space is much smaller than the structure space, and identification of common shapes can be done in linear time (in the number of shapes considered), the method is essentially linear in the number of sequences. See [ree:gie:2005] for details.
Should no common shape be reported, try to increase the amount of shape spaces being inspected via parameters relative deviation or absolute deviation.
eval
Evaluates the free energy of an RNA molecule in fixed secondary structure, similar to RNAeval from the Vienna group.
Multiple answers stem from semantic ambiguity of the underlying grammar. It might happen, that your given structure is not a structure for the sequence. Maybe your settings are too restrictive, e.g. not allowing lonely base-pairs (lonely base pairs).
If you input a (multiple) FASTA file, RNAalishapes assumes that exactly first half of the contents of each entry is RNA sequence, second half is the according structure. Whitespaces are ignored.
abstract
Abstracts a Vienna-Dot-Bracket representation of a secondary structure into a shape string.
outside
Applies the "outside"-algorithm to compute probabilities for all base pairs (i,j), based on the partition function [mcc:1990]. Output is a PostScript file, visualizing these probabilities as a "dot plot".
mea
Finds the secondary structure with the maximal sum of base-pair probabilities (MEA=maximal expected accuracy). The equivalent Vienna Package name is the 'centroid secondary structure', defined as 'The centroid structure is the structure with the minimum total base-pair distance to all structures in the thermodynamic ensemble.'.
probing
Structural probing is a wet-lab method to obtain hints about the likelihood of a nucleotide in a structure to be unpaired, a so called 'reactivity' [wee:2010]. We use the reactivities to enrich the thermodynamic model. To circumvent the challenge of properly weighting free energies and reactivities, as in e.g. RNAstructure [dei:li:mat:wee:2009], we compute a pareto front of both optimization criteria [sau:gie:2015]. This returns a set of equally good candidates, which represent interesting spots of the structural ensemble. Finally, the user has to pick his or her favorite.
In-/Output values
INPUT :: RNA sequence(s)
A (multiple) FASTA file, containing RNA primary sequences.
INPUT :: RNA secondary structure
A Vienna dot-bracket formatted string, representing a seconday RNA structure.
INPUT :: RNA sequence
Exactly one RNA primary sequence.
INPUT :: RNA family
A family of at least two potentially related RNA sequences. This is not an alignment, since sequences can have different lengths.
INPUT :: reactivity file
A file containing the raw reactivity values. The file must contain two tabular separated columns. First column is the index of the nucleotide, starting with 1. The second column is a float value giving the reactivity for that nucleotide. There must be as many rows as nucleotides in the input RNA sequence!
OUTPUT :: output
Example output
The following image shows the output of the example call RNAshapes --windowS=50 --windowI=20 --mode=probs --structureProbs=1 < example.mfa Colored elements are not part of the output.
You get two "answers" for the two input sequences, contained in "example.mfa". Each answer starts with an "identification line" (orange). Computation was done in window style, thus you see two different "result blocks" for each sequence, separated by newlines and sorted by "start position". (If input sequences have different lengths, output has different number of result blocks for the sequences). Each result blocks has one "window info line" (green) and one or more "result lines" (blue). Lines are further divided into "fields", by two white space characters (red vertical lines). Contents of the fields are:
identification line
sequence name: first character is the FASTA typical >, followed by the name of the sequence.
window info line
start position. Due to lengthy scores in result lines, start position has often leading white space characters.
"representative" is the sub-sequence that has been computed in this result block
"stop position"
result line
"free energy" in kcal/mol
individual "structure probability" only if switched on via parameter structure probabilities
Vienna-Dot-Bracket representation of the secondary "structure".
"shape probability" for the shape class, that is represented by the structure
"shape string" of the structure
Name
Description
mfe
Each result block contains only one result line, showing minimal free energy structure. Co-optimal results and shape probabilities are not computed for the sake of speed and thus not displayed.
subopt
Similar to mfe output, but each block can hold several result lines for sub-optimal structures. They are ascendingly sorted by their free energy.
shapes
Similar to subopt output, but structures with same shape strings are grouped. Result lines show the best member of a shape class (called "shrep"), which is determined by its free energy.
probs
Output as in the above example, result lines are descendingly sorted by shape probabilities
sample
Identical to probs output, since it computes the same information, but in a heuristic fashion.
Should you be interested in the concrete sampled structures, you can report them via option show samples. Output will have normal window info line, followed by the line
$1 samples, drawn by stochastic backtrace to estimate shape frequencies:
, where $1 is the value of numSamples. Traditional result lines begin after the line
Sampling results:
, which is surrounded by empty lines.
cast
Output of cast has its very own format, because your input is a family of related RNA sequences and result is common shapes for all family members. Here is an example output for the call RNAshapes --mode=cast --abs 4.5 --structureProbs=1 < example.mfa
1)
Shape: []
Score: -35.00
Ratio of MFE: 0.92
>seq1
1
CACACAAAGGCAGCGGAACCCCCCUCCUGGUAACAGGAGCCU
42
-10.00
0.1124677
.......................((((((....))))))...
R: 2
[]
>seq2
1
AGGCAGCGGAAAUCCCCACCUGGUAACAGGUGCCUCUGC
39
-15.20
0.9246810
..((((.((.......((((((....)))))))).))))
R: 1
[]
>seq3
1
CCUUUGCAGGCAGCGGAAUCCCCCACCUGGUGACAGGUGCCU
42
-9.80
0.0068363
.......................((((((....))))))...
R: 3
[]
2)
Shape: [[][]]
Score: -30.00
Ratio of MFE: 0.79
>seq1
1
CACACAAAGGCAGCGGAACCCCCCUCCUGGUAACAGGAGCCU
42
-9.60
0.0587713
.......((((...((....))..(((((....)))))))))
R: 3
[[][]]
>seq2
1
AGGCAGCGGAAAUCCCCACCUGGUAACAGGUGCCUCUGC
39
-11.70
0.0011937
..((((.((....)).((((((....))))))...))))
R: 2
[[][]]
>seq3
1
CCUUUGCAGGCAGCGGAAUCCCCCACCUGGUGACAGGUGCCU
42
-9.00
0.0030373
.......(((((..((......)).((((....)))))))))
R: 4
[[][]]
The RNA family might have several common shapes (two in the example), which are sorted by their combined free energy, called "Score". For each common shape the following lines are printed:
"common shape line", with fields:
Rank of common shape
common shape string
the Score of the common shape, which is the sum of free energies of the family member sequences.
Ratio of MFE, which is the Score divided by the sum of all minimal free energies of all family members, indendent of their shape class, i.e. if freely folded.
one identification line per family member
one window info line per family member
one result line per family member, where third field is the Rank of the shape class in shape mode
eval
Similar to mfe output, but should your grammar be semantically ambiguous (as "microstate" is) regarding Vienna-Dot-Bracket strings, you will get several result lines. Please note that window style input would be nonsense, thus you get only one result block.
abstract
Output is just one line, holding the shape string for the given secondary structure. Again, window style input is nonsense
outside
Outside mode produces a PostScript file, holding the probabilities of the base-pairs. The "dot plot" shows a matrix of squares with area proportional to the base pair probabilities in the upper right half. For each pair (i,j) with probability above bppmThreshold there is a line of the form
i j sqrt(p) ubox
in the PostScript file, so that they can be easily extracted.
mea
Similar to mfe output. May contain several result lines due to co-optimal structures. The field "structure probability" here holds the sum of the MEA structures base-pairs, not the structure probability as in the other modes.
probing
Regarding the format, it is similar to the subopt output, aside from an additional second field in the result lines. It reports the sum of reactivities for all paired and unpaired nucleotides. Number of decimals can be set via decimals for probabilities. Contrary to the subopt mode, the multiple result lines stem from the fact, that a Pareto front has been computed. This is the outcome of an optimization regarding the two independent optimization critera "minimization of free energies" and "maximization of reactivity sums".
relative deviation sets the energy range as percentage value of the minimum free energy. For example, when relative deviation is specified as 5.0, and the minimum free energy is -10.0 kcal/mol, the energy range is set to -9.5 to -10.0 kcal/mol.
relative deviation must be a positive floating point number; by default it is set to to 10 %.
This sets the energy range as an absolute value of the minimum free energy. For example, when absolute deviation 10.0 kcal/mol is specified, and the minimum free energy is -10.0 kcal/mol, the energy range is set to 0.0 to -10.0 kcal/mol.
absolute deviation must be a positive floating point number. Cannot be combined with relative deviation.
low probability filter sets a barrier for filtering out results with very low probabilities during calculation. The default value here is 0.000001, which gives a significant speedup compared to a disabled filter. Note that by turning on this filter, results are no longer guaranteed to be exact. This also influences shapes which have not been filtered out. For technical details, see [vos:gie:reh:2006]
Only floating point values between 0 and 1 are allowed, excluding 1.0, because otherwise virtually all results would be filtered out.
output probability filter sets a filter for omitting low probability results during output. It is just for reporting convenience. Unlike low probability filter, this option does not have any influence on runtime or probabilities beyond this value.
Only floating point values between 0 and 1 are allowed, excluding 1.0, because otherwise virtually all results would be filtered out.
If activated, in addition to free energy also the probability of individual structures will be computed. To speed up computation, this calculation is switched off by default.
In MEA mode, the given probability is the sum of the base-pair probabilities used by the computed MEA structure and thus will likely be larger than 1.
How to treat dangling end energies for bases adjacent to helices in free ends and multi-loops.
nodangle: (-d 0 in Vienna package) ignores dangling energies altogether.
overdangle: (-d 2 in Vienna package) always dangles bases onto helices, even if they are part of neighbouring helices themselves. Seems to be wrong, but could perform surprisingly well.
microstate: (-d 1 in Vienna package) correct optimization of all dangling possibilities, unfortunately this results in an semantically ambiguous search space regarding Vienna-Dot-Bracket notations.
macrostate: (no correspondens in Vienna package) same as microstate, while staying unambiguous. Unfortunately, mfe computation violates Bellman's principle of optimality.
shape level is the level of abstraction or dissimilarity which defines a different shape. In general, helical regions are depicted by a pair of opening and closing brackets and unpaired regions are represented as a single underscore. The differences of the shape types are due to whether a structural element (bulge loop, internal loop, multiloop, hairpin loop, stacking region and external loop) contributes to the shape representation: Five types are implemented. Their differences are shown in the following example:
The energy parameters used in the calculation have been measured at 37 C. Parameters at other temperatures can be extrapolated, but for temperatures far from 37 C results will be increasingly unreliable.
Read energy parameters from a file, instead of using the default parameter set. See the RNAlib (Vienna RNA package) documentation for details on the file format.
Lonely base pairs have no stabilising effect, because they cannot stack on another pair, but they heavily increase the size of the folding space. Thus, we normally forbid them. Should you want to allow them set lonely base pairs to 1.
lonely base pairs must be either 0 (=don't allow lonely base pairs) or 1 (= allow them).
Instead of running the computation for the whole input sequence, you can apply a window style.
Imagine your input is a 4 mega bases genome, but you are looking for e.g. t-RNA, which is a small cloverleaf structure of say 80 bases. You don't want to have one prediction for the complete 4 MB genome, but predictions for 80 bases long parts of the genome.
If you input a positive window size, window style will be activated - as described above. After computation for the current window is done, it will be shifted by X bases to the right and computation for the next window starts. X can be modified via parameter window increment.
Overlapping parts are internally reused to save compute time.
Once you activate window style, by setting window size to a positive integer value, the sliding window will be shifted by X bases to the right after a window is computed. You can modify X with the parameter window increment.
Since there must be a overlap of at least one base between two windows,
window increment must be smaller than
window size. Only positive integer values are allowed.
The program RNAstructure [dei:li:mat:wee:2009] adds a bonus to the free energy of a base-pair stack according to the formula: bonus = slope * log(reactivity + 1) + intercept. If you set the parameter normalization to the value "RNAstructure", reactivities are normalized according to this spirit, but added for all base-pairs and substracted for all unpaired bases.
The reactivities read from a file (see input reactivity file) can be normalized in four ways. Non zero values are always set to be 0.0.
"centroid": a 2-means clustering of all raw reactivities gives a centroid value for 'paired' and another for 'unpaired' values. The difference to the respective centroid, given by the structure, is added to the score.
"asProbabilities": All reactivities are converted into probabilities ranging from 0.0 to 1.0.
"logplain": reactivities are transformed via the formula: log(reactivity + 1.0).
"RNAstructure": reactivities are normalized as in the program RNAstructure, i.e. basically by the formula: slope * log(reactivity + 1) + intercept
The modifier is the chemical reagent in a structure probing experiment that attacs the nucleotide which in the end gives its reactivity. Different modifier affect different bases. Reactivities given by the input reactivity file will be set to zero if the modifier cannot affect a base. Available modifiers are: